

OpenAI Price Drop: [Another] Megathread
Today's 90% drop on ChatGPT API – aka gpt-3.5-turbo – is another before & after moment in AI
Nathan Labenz is channeling his inner DJ Khaled and dropping another one - that’d be another megathread on OpenAI’s pricing.
Nathan explains the price drop on Open AI’s ChatGPT API, how it happened and what it means.
For context, this comes on the heels of a 2/3rds price reduction last year. A 96.6% total reduction in less than a year.
I am on record predicting low prices, but even I didn't expect another 90% price drop this soon.
Tyler Cowen quoted my last tweet thread (below) on OpenAI’s pricing in his publication Marginal Revolution.


And OpenAI didn't have to do this, at least not yet – business is booming as every company in the world races to implement AI and most see OpenAI as the obvious choice.
Some sophisticated customers are developing cheaper alternatives, but most are still happy paying the $0.02.


This move puts OpenAI's price at a fraction of their most direct competitors' prices, just as competitors are starting to ramp up.
Driving costs so low so quickly will make things very difficult for non-hyperscalers. How are they ever supposed to recoup all that fixed training cost??
To compare foundation model prices across providers, I created this document. Feel free to make a copy and plug in your own usage patterns.
Notably, the 90% cheaper model is slightly worse than its closest comparable. OpenAI implicitly acknowledges this in their Chat Completion Guide:
"Because gpt-3.5-turbo performs at a similar capability to text-davinci-003 but at 10% the price per token, we recommend gpt-3.5-turbo for most use cases."

And indeed, I've noticed in my very quick initial testing that it cannot follow some rather complex / intricate formatting instructions that text-davinci-003 can follow successfully. Fwiw, Claude from Anthropic can also follow these instructions, and that is the only other model I currently know of that can.
Pro tip: when evaluating new models, it helps to have a set of go-to prompts that you know well. I can get a pretty good sense for relative strengths and weaknesses in a few interactions this way.
How did this happen? Simple really – "Through a series of system-wide optimizations, we’ve achieved 90% cost reduction for ChatGPT since December; we’re now passing through those savings to API users."
Since December? That can't be literally true. I'm sure the work was in progress before.
Though, I could imagine that the unprecedented inference data they've gathered via ChatGPT over the last few months might be useful for powering a combination of distillation and pruning procedures that could bring parameter size down significantly.
Perhaps related: OpenAI apparently has all the data it needs, thank you very much.
Perhaps having so much data that you no longer need to use retain or use customer data in model training is the real moat?

What does this mean???
For one thing, it's a version of Universal Basic Intelligence. Sure, it's not open, but it's getting pretty close to free.
For the global poor, this is a huge win. Chat interactions that consist of multiple rounds of multiple paragraphs will now cost just a fraction of a cent. For a nickel / day, people can have all the AI chat they need.
A lot of "AI will exacerbate economic inequality" takes ought to be rethought.
Concentration among AI owners may be highly unequal, but access is getting democratized extremely quickly.
The educational possibilities alone are incredible, and indeed OpenAI highlights the global learning platform Quizlet, which is launching "a fully-adaptive AI tutor" today.
"Quizlet is a global learning platform with more than 60 million students using it to study, practice and master whatever they’re learning. Quizlet has worked with OpenAI for the last three years, leveraging GPT-3 across multiple use cases, including vocabulary learning and practice tests. With the launch of ChatGPT API, Quizlet is introducing Q-Chat, a fully-adaptive AI tutor that engages students with adaptive questions based on relevant study materials delivered through a fun chat experience."
In the rich world, AI was already cheap. Now, it's going to be super abundant. But one thing that is missing at this price level: fine-tuning! For the turbo version, you'll have to make do with old-fashioned prompt engineering. The default voice of ChatGPT will be everywhere.
Every product is going to be talking to us, generating multiple versions, proactively offering variations, and suggesting the next actions. Executed poorly it will be overwhelming, executed well it will feel effortless.
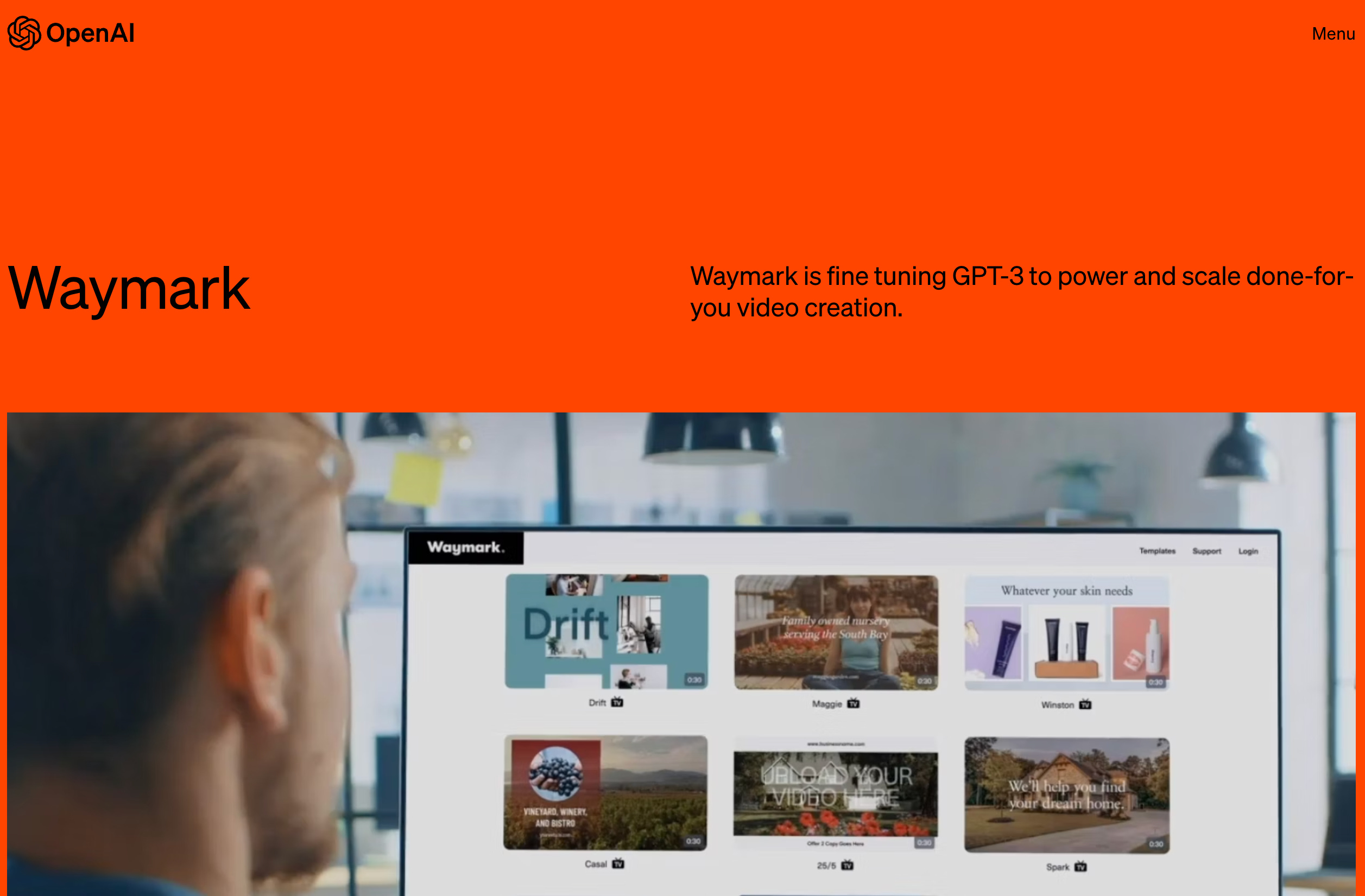
Have to shout out my own company, Waymark, as a great example here. We had the vision for a "Watch first" video creation experience years ago, and we now combine a bunch of different AIs to make it possible.
And while it wasn't the biggest news OpenAI made this week, they did revamp their website to highlight customer stories, and we were genuinely honored to be featured!
I've already written a note in our #strategy slack channel about increasing the number of videos we make each time you submit an idea.
But this goes way beyond content.
Agent / bot frameworks like LangChain and Promptable, and companies like soon-to-launch Fixie.ai are huge winners here too
AI coding and auto-debugging are amazing conceptually but I've seen them in action and it often looks even clumsier than human debugging. A lot of calls, but … that matters a lot less now
It follows that AI bot traffic is going to absolutely explode. I have a vision of langchain lobsters, just smart enough to slowly stumble around the web until they accomplish their goals.
The upshot of this: OpenAI revenue might not drop as much as you'd think.
A related anecdote from The Cognitive Revolution podcast (@cogrev_podcast): Suhail Doshi (@suhail) told us that when Playground AI (@playgroundai) eliminated a bottleneck, making the service twice as fast, they immediately saw 2X as much image generation volume. Something like that might happen here.

Vector databases like Chroma (@trychroma) win too. The cheaper tokens become, the more context you can stuff into prompts, and the more it makes sense to just embed everything and figure it out on the fly.
Learn all about vector databases with Anton (@atroyn) on our latest episode, out today!



To give you a sense of the volume of usage that OpenAI is expecting… they also announced dedicated instances that "can make economic sense for developers running beyond ~450M tokens per day."
That's a lot!
As I said the other day, longer context windows and especially "robust fine-tuning" seem to be OpenAI's core price discrimination strategy, and I think it's very likely to work.
While essay writers in India pay a tenth of a penny for homework help, corporate customers will pay 1-2 orders of magnitude more for the ability to really dial in the capabilities they want.
And in some cases, I bet they'll pay 3 orders of magnitude more simply because their workload doesn't take full advantage of their dedicated compute. Most businesses don't run equally 24/7.
One wonders what OpenAI might do with that compute when it's not in use… Safe to say they won't be mining bitcoin.
For open source? This takes some air out of open source model projects – when a quality hosted version that runs fast and reliability is so cheap, who needs the comparative hassle of open source? – but open-source will remain strong. It's driven by more than money.
And importantly, the open source community is increasingly capable of doing more than imitating OpenAI.
The best AI podcast of 2023 is the NoPriors interview with Emad, in which he articulates a truly beautiful, inspiring vision for a Cambrian explosion of small models, each customized to its respective niche. Highly recommended!

Obviously, the number of prompt engineer job listings will continue to soar, for a while longer at least.
If you want to break into the game, I recommend Learn Prompting.
Very clear explanations, natural progression, and thoughtful examples.
Finally, for now, thank you for reading! Comments & messages have been overwhelmingly positive!
Here's my podcast: The Cognitive Revolution.
Soon, we'll have Junnan and Dongxu of BLIP & BLIP2, Aravind of Perplexity, Elad Gil and Sarah Guo of No Priors, Jungwon of Elicit.
March 2, 2023: This was written by Nathan Labenz, founder of Waymark and host of The Cognitive Revolution podcast